[제1회 팩트체크주간] 인공지능
2021년 4월 5일 시청자미디어재단에서 주최한 “제1회 팩트체크 주간"의 두 번째 날 행사에서 인공지능을 활용한 팩트체크 기술에 관한 발표와 토론이 진행됐다.
유튜브와 줌(ZOOM)을 통해 생중계된 이날 주제에서 네이물 하싼(Naeemul Hassan) 미국 메릴랜드 대학 교수는 기계학습 팩트체킹 시스템인 ‘클레임버스터’(ClaimBurster)‘를 활용해 토론 프로그램을 사실검증한 사례를 발표했고, 서울대학교 팩트체크 연구팀은 국내 처음으로 개발중인 팩트체크 시스템을 소개했다.
주제 발표에 앞서 인공지능 팩트체크의 의미를 설명한 이선민 시청자미디어재단 선임 연구원은 많은 사람들이 오랜 시간을 들여 일일이 사실을 검증해야 하는 팩트체크 작업을 인공지능을 활용해 더 효율화시킬 수 있다고 말했다.
첫 발표자로 나선 하싼 교수가 소개한 클레임버스터는 인공지능을 기반으로 하는 팩트체크 프로그램이다. 미국 텍사스 대학과 듀크 대학, 스탠포드 대학 연구진이 2015년부터 협력해 만든 클레임버스터는 팩트체크 자동화 기술과 관련해 국내의 많은 연구자들이 참고하는 모델이다. 이 프로젝트를 주도하고 있는 하싼 교수는 많은 정치인들의 주장을 일일이 검증하는 일은 불가능하다며 이를 효율적으로 도울 수 있는 팩트체크 프로그램을 개발하기위해 클레임버스터를 만들었다고 말했다.
대선 녹취록 자료를 활용한 자동화 팩트체킹
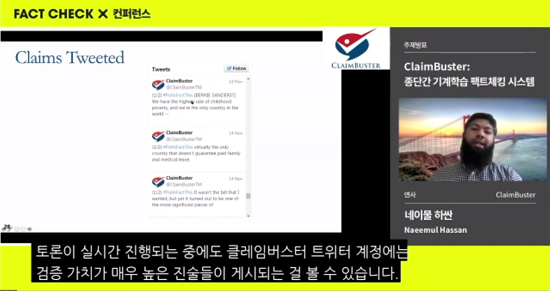
하싼 교수는 클레임버스터 프로그램 안에 입력된 토론과 인터뷰, 진술 녹취록에서 나온 사실과 주장들을 식별해 팩트체킹의 시간을 절약할 수 있다고 말했다. 그는 저널리스트 전문가들이 2천여 개의 주장을 읽는 데 20~30분이 걸리지만 클레임버스터는 1분 또는 몇 초안에 사실 검증에 필요한 상위 10개 사실을 선별할 수 있다고 말했다. 그가 주도한 연구팀은 클레임버스터를 설계하기 위해 1960년대에서 2012년까지의 대통령 선거와 관련한 토론과 인터뷰 등의 진술로 구성된 녹취록 33개를 수집해 기계학습 알고리즘을 활용하여 대선 후보들이 말한 2만여 개의 문장을 확보했다. 이를 바탕으로 ‘중요한 사실’과 ‘중요하지 않은 사실’, ‘사실이 아닌 진술’의 세 가지 범주로 분류해 검증 가치의 정도에 따라 0에서 1 사이의 범위 내에서 점수를 매겨 팩트체크를 할 수 있다고 설명했다.

실시간으로 토론 현장 분석해 사실 검증
하싼 교수의 설명에 따르면 클레임버스터 프로그램을 이용해 대선 후보 토론 방송을 분석해 발언 내용의 사실을 검증하는 데 쓰이고 있다.클레임버스터는 텔레비전에 나오는 자막이나 캡션을 추출해 자체 기계학습 모형에 입력하고, 이를 통해 사실을 검증하여 점수로 나타낸다.
국내 최초 한국어 기반 팩트체크 프로그램 생성
뒤이어 발표한 이준환 서울대 언론정보학과 교수와 오종환 서울대 융합과학기술대학원 연구원은 국내 처음으로 구축한 ‘한국어 팩트체크 데이터세트’를 소개했다. 2020년에 구축된 이 데이터세터는 알고리즘을 기반으로 한 팩트체크 기술을 활용해 어떠한 주장을 참과 거짓으로 판단하고 이를 뒷받침할 근거 자료를 도출한다. 이준환 교수는 “김구는 해주에서 태어났다”라는 문장을 예로 들었다. ‘한국어 팩트체크 데이터세트’는 위키피디아에 수록된 관련 정보를 토대로 이 문장의 참과 거짓을 판단하는 데 활용된다.
이 교수는 데이터세트를 구축하는 과정에서 얻은 연구 결과가 앞으로 또다른 데이터세트를 만드는 일에도 도움이 될 것이라고 덧붙였다.

한국어 기반 팩트체크 기술 한계 여전히 존재해
다만 이준환 교수는 이번에 개발한 데이터 세트가 기존의 데이터 아카이브를 통해서만 사실 여부를 검증한다는 한계가 있다고 설명했다. 따라서 앞으로 팩트검증의 소스가 되는 고품질 데이터베이스를 구축하는 것이 중요하다고 강조했다.
주제 발표에 이어진 토론에서 학자들은 인공지능을 활용한 팩트체킹의 기술적 한계를 주로 지적했다. 토론에서도 황용석 건국대 교수는 인공지능을 활용한 팩트체크의 활용 방안에 관해 “진실은 움직이는 표적과 같은 것”이라며 “언론인들이 다루고 있는 정보들은 그동안 학습되지 않는 데이터들이기 때문에 진실을 예측하거나 사실을 찾을 수 있는 시스템을 만들 수 없는 상황”이라고 말했다. 오세욱 한국언론진흥재단 선임연구원도 “아직은 인간의 의사결정에 도움을 주는 조력자로서 (참과 거짓의) 확률을 가늠하는 수준으로 인공지능 기술이 쓰일 것이다”고 말했다.
인공지능 팩트체킹의 기초부터 닦아야 한다는 주문도 나왔다. 황용석 교수는 정부에서 추진하는 ‘데이터댐 사업’이나 ‘디지털 뉴딜 정책’에 투자가 많이 이뤄지고 지고 있는 상황에서 공공 데이터에 더욱 쉽게 접근하고 편리하게 검색할 수 있는 시스템을 만드는 것이 중요하다고 지적했다.
이날 진행된 컨퍼런스는 시청자미디어재단 유튜브 채널을 통해 다시 볼 수 있다.
편집: 김병준 PD